Radu, thank you for helping me with this problem!
My beloved power distribution company had always have problems. It is common thing to have a power outage up to half an hour every few weeks. Lately however, the problems increased in rate and gravity. I don't know exactly what happened last time, but there were 2 power outages in 30 minutes and 6 in 24 hours. Voltage peaks and spikes, variations in the frequency and everything. The result: the UPS and one disk were broken. What doesn't kill you makes you stronger. I guess mine were not strong enough for this challenge. I also had a very old HITACHI disk which was already showing signs of failure (part of an RAID1 array) .
So I decided to replace both disks. This is a piece of cake operation, isn't it? It wasn't because the server was located in Romania and I am in Sweden.
After removing the faulty disk from the array and shutting down the server
[codesyntax lang="bash"]
mdadm /dev/md0 --fail /dev/sdb1 --remove /dev/sdb1
mdadm /dev/md1 --fail /dev/sdb2 --remove /dev/sdb2
mdadm /dev/md2 --fail /dev/sdb3 --remove /dev/sdb3
[/codesyntax]
I asked a friend of mine to physically replace the disk.
Then I re-added the disk in array
[codesyntax lang="bash"]
mdadm --add /dev/md0 /dev/sdb1
mdadm --add /dev/md1 /dev/sdb2
mdadm --add /dev/md2 /dev/sdb3
[/codesyntax]
and waited to sync.
[codesyntax lang="bash"]
echo 100000 > /proc/sys/dev/raid/speed_limit_min
watch -n1 cat /proc/mdstat
[/codesyntax]
The next thing was to reboot the server to make sure everything was fine.
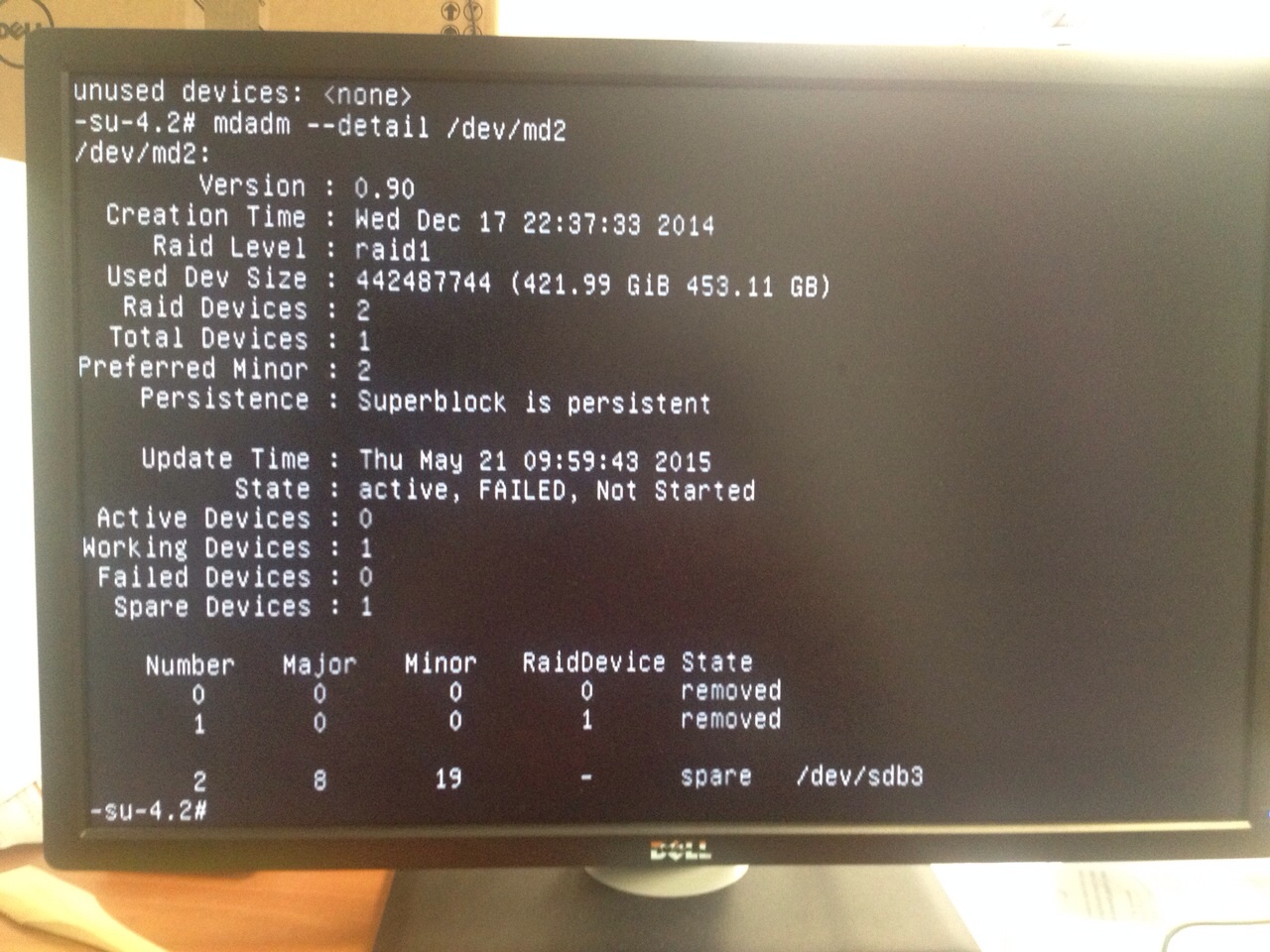
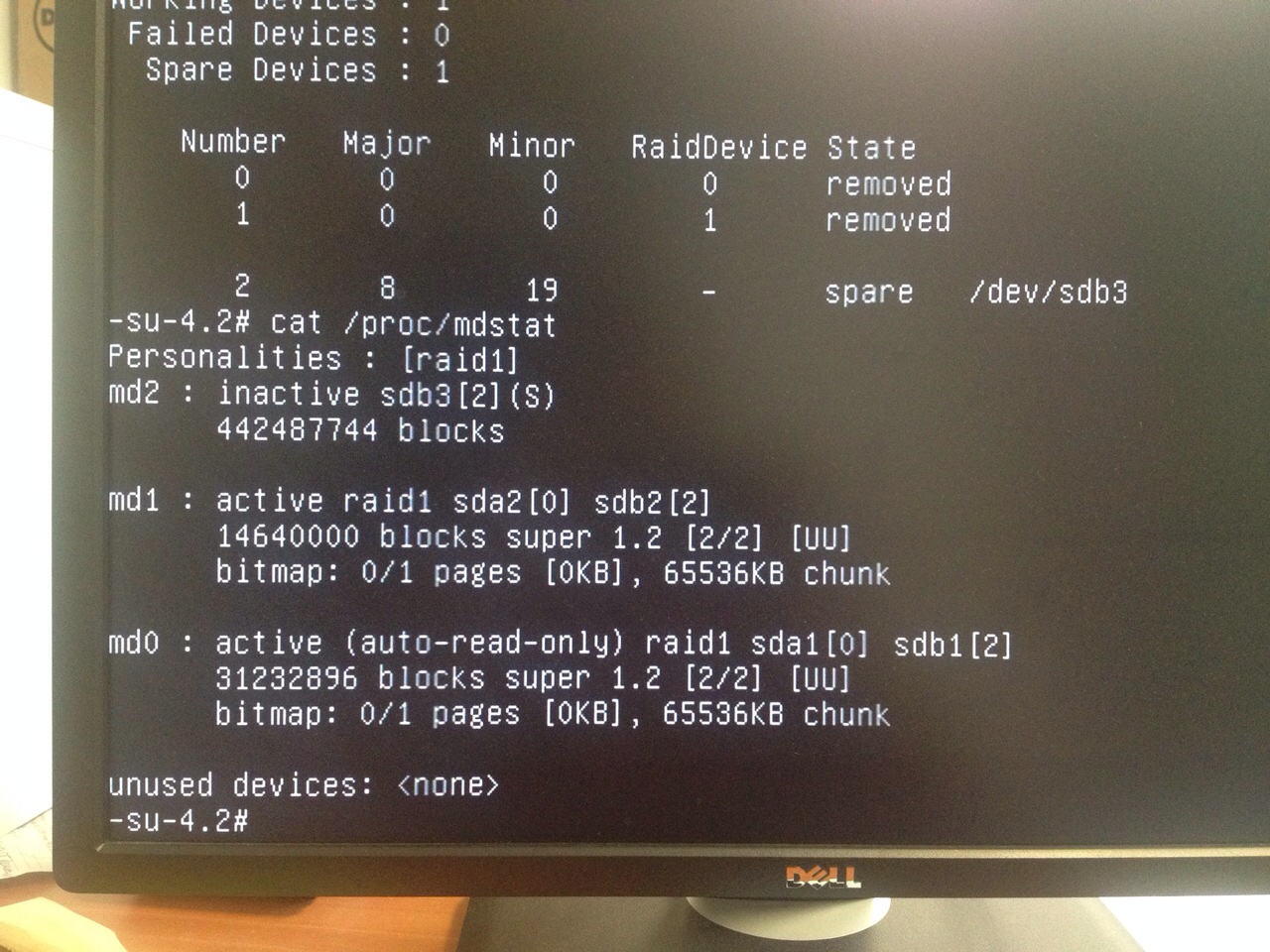
Well, it wasn't fine. I couldn't connect to the server, so something happened with the filesystem, raid or whatever.
After having a chat with my friend from Romania I find out that there was a problem with /dev/md2.
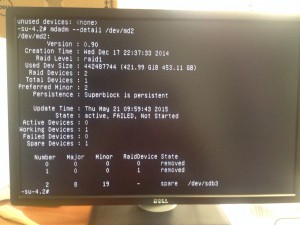
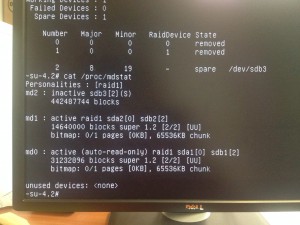
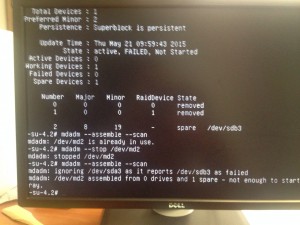
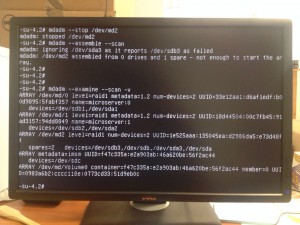
Something really strange was going on.
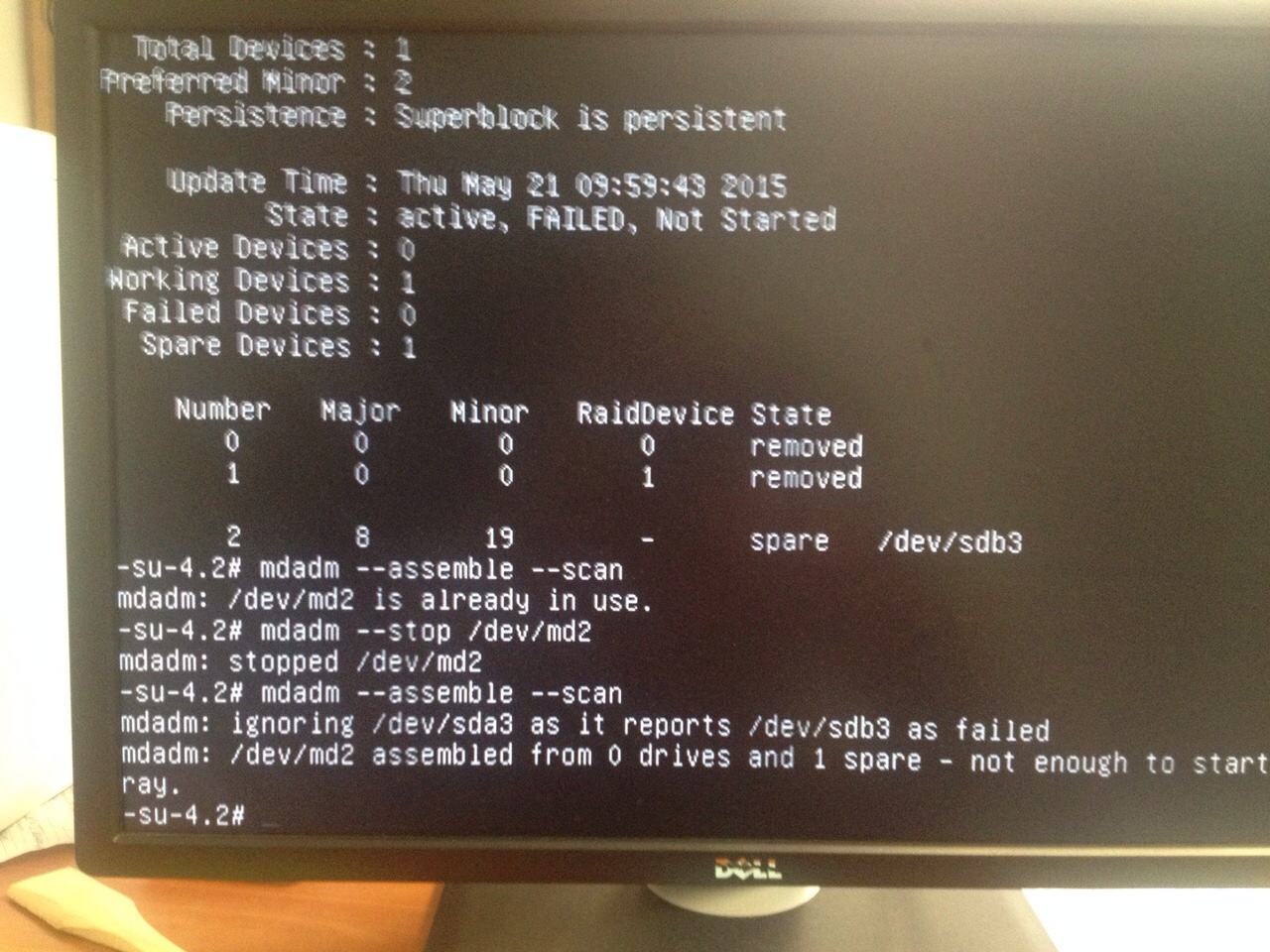
We tried different things like removing and re-adding the disk, --zero-superblock the new disk... More or less the same error.
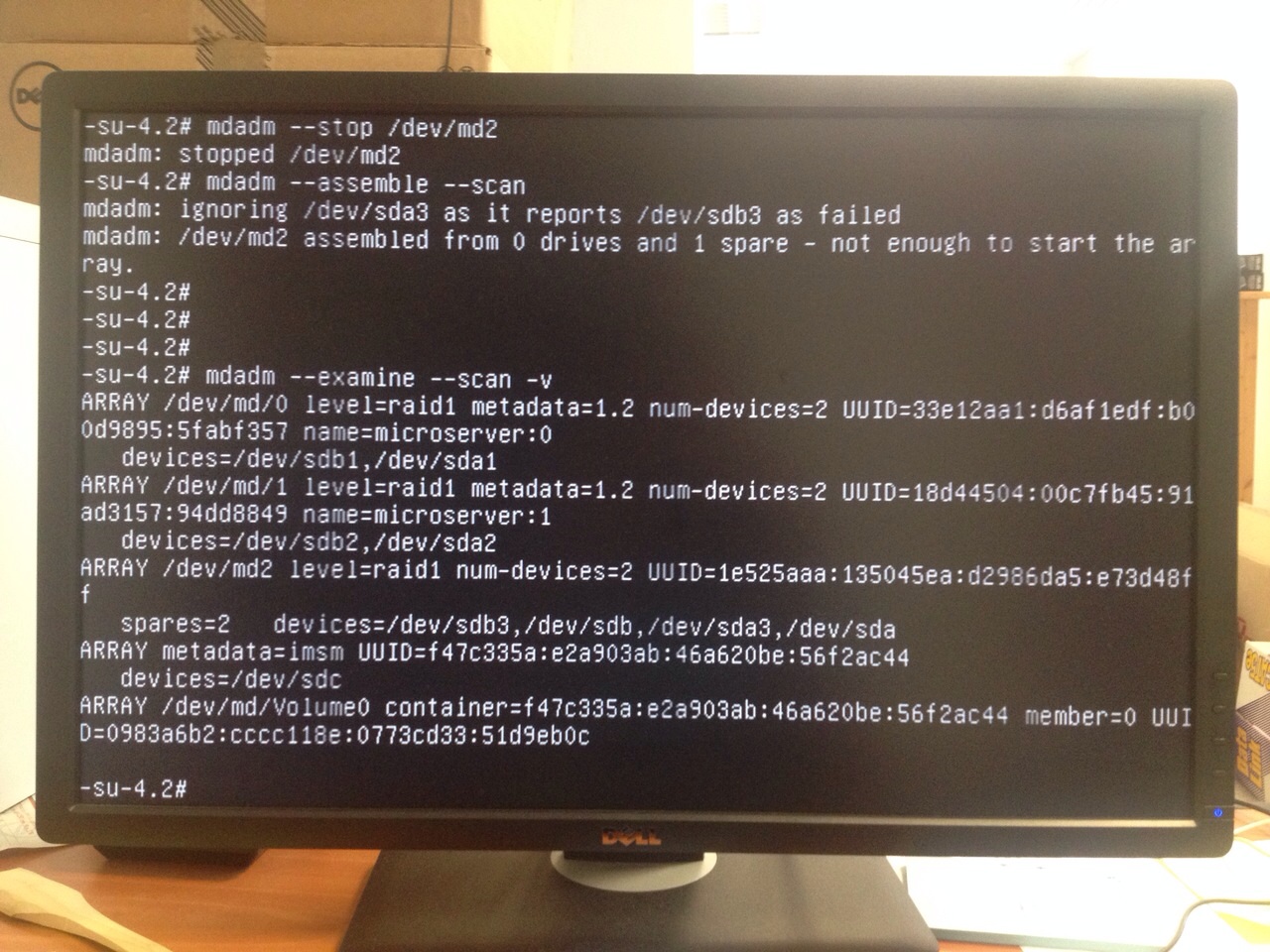
When I was out of ideas and just about to give up when I received this messages from my friend "I fixed it for you!!!! Apparently there is a bug in metadata 0.90 and you have to use 1.2, but you can't choose metadata version with the debian installer. I sent you an email. Read it!".
Basically the email with the solution contained only one line: http://serverfault.com/questions/265056/mdadm-assembles-with-drives-instead-of-partitions
After he added DEVICE ... to /etc/mdadm/mdadm.conf the problem was solved.
[codesyntax lang="bash"]
vim /etc/mdadm/mdadm.conf
[/codesyntax]
DEVICE /dev/sda1
DEVICE /dev/sda2
DEVICE /dev/sda3
DEVICE /dev/sdb1
DEVICE /dev/sdb2
DEVICE /dev/sdb3
Recent Comments